
8. Fitting schemes
A fitting scheme is a way of pre-processing the raw dataset. The pre-processed data set will be fitted with the standard spectra resulting in better fit results and more accurate nuclide concentrations.
Important note
The fitting schemes only apply to the fields related to the radionuclides. All other fields in the dataset are averaged and not processed according to the scheme selected.
Fit each
Fit each is the most basic fitting scheme. Every spectrum in the raw dataset is fitted with the standard spectrum without averaging or applying any kind of calculation to the dataset.
Smart fit
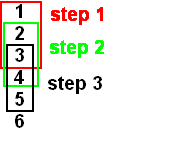
Smart fit is a more advanced scheme. It calculates the running average of the nuclide information in the dataset. The number of data points used for the running average is entered in the smart fit factor field. For example, the image below shows a simplified dataset indicated with the numbers one to six. The smart fit factor chosen is 3, three data points are selected and the average is calculated. In the next step again three data points are selected but the selection moves down one column. This process is repeated until the end of the dataset is reached.
Repeated average
The repeated average scheme calculates the (ordinary) average and combines a number of data points. The number of data points to average can be entered in the '# of records to average' field. For example: processing a raw dataset containing 20.000 data points using 5 records to average will contain 4.000 data points.
Conditional summing
Conditional summing will sum the spectra until the specified standard deviation is reached.
Traditional fit
The traditional fit method only uses the specified energy window to determine the nuclide concentrations. The algorithm assumes the peak of the nuclide concentration is in the energy window specified. The full spectrum is not used.